
Glycoproteomics: Unveiling the Sugar Code of Proteins
1. Glycoproteomics: Understanding the Sugar Code of Proteins
In modern biology, the concept of the “sugar code” is becoming as important as the genetic code itself. While DNA and proteins have long been the focus of biomedical research, it is now clear that complex carbohydrate structures attached to proteins — known as glycans — also carry vital information. These sugar chains do not merely decorate proteins; they determine how proteins fold, where they travel in the cell, how long they remain stable, and how they interact with other molecules.
Glycoproteomics is the scientific field dedicated to mapping and understanding these glycan–protein relationships. It bridges proteomics (the large-scale study of proteins) and glycomics (the study of glycans), creating an integrated view of how protein glycosylation shapes biology. By combining advanced mass spectrometry, enrichment strategies, and computational tools, glycoproteomics aims to decode the structural language of glycans and translate it into biological meaning.
The importance of this field extends far beyond academic curiosity. Aberrant glycosylation patterns are tightly linked to diseases such as cancer, autoimmune disorders, and congenital glycosylation deficiencies. In oncology, for example, changes in glycan branching or sialylation can signal tumor progression, making glycoproteomics a powerful approach for discovering new biomarkers. Similarly, in therapeutic protein development, precise control over glycosylation is critical to ensure safety, stability, and efficacy.
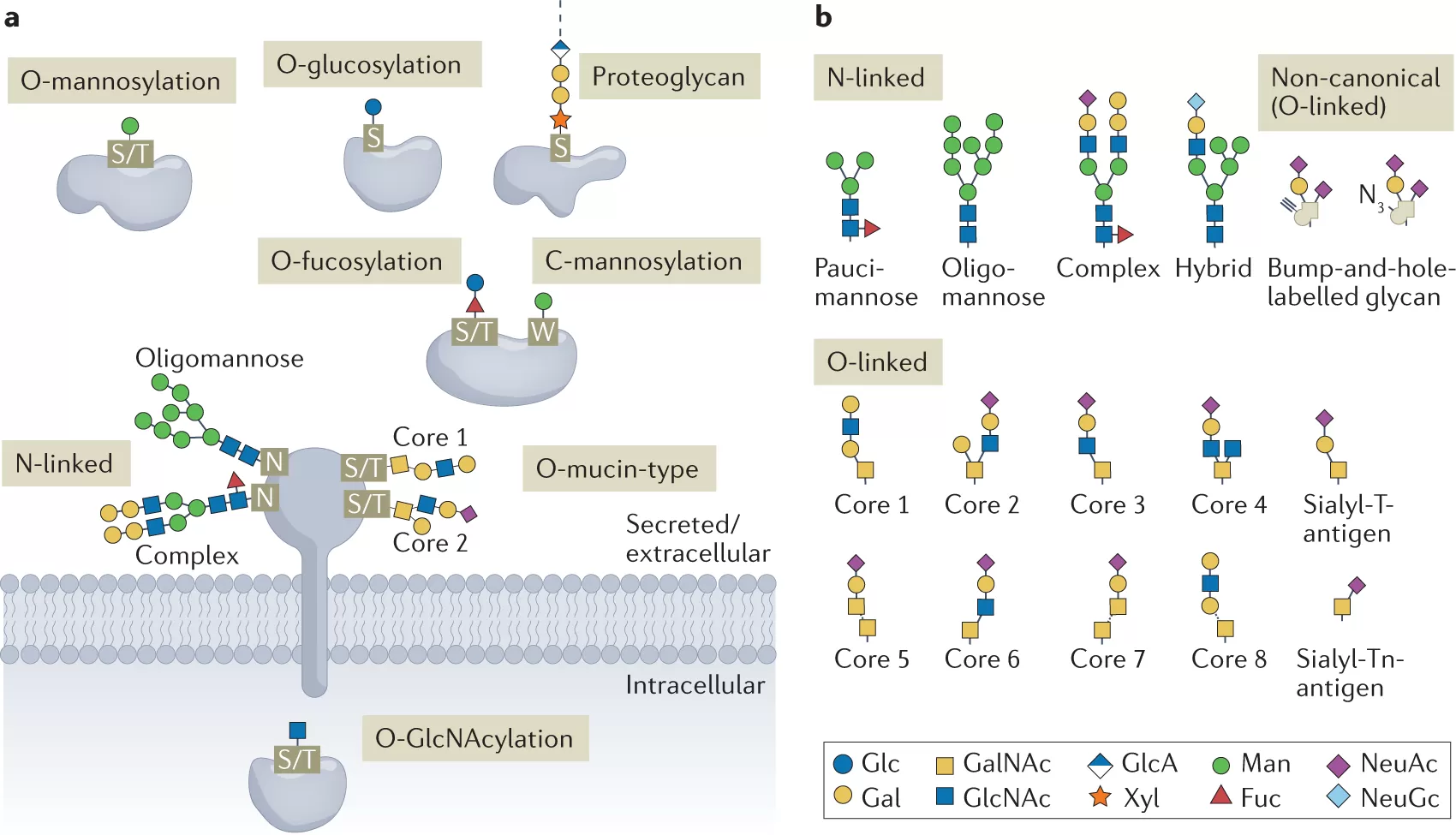
Glycoproteomics (Bagdonaite et al., 2022)
2. The Biology of Protein Glycosylation
Protein glycosylation is one of the most widespread and diverse post-translational modifications in eukaryotic cells. It refers to the covalent attachment of carbohydrate chains (glycans) to specific amino acid residues on proteins. Unlike the linear, template-driven synthesis of DNA or proteins, glycosylation is a non-template process, producing an extraordinary degree of structural complexity and heterogeneity. This diversity underpins the concept of the “sugar code,” where subtle variations in glycan structure can profoundly alter biological outcomes.
2.1 Types of Glycosylation
The two most common forms are:
-
N-linked glycosylation – attachment of glycans to the nitrogen atom of asparagine residues within a specific consensus sequence (Asn-X-Ser/Thr). N-glycans are typically processed in the endoplasmic reticulum and Golgi apparatus, generating high-mannose, hybrid, or complex glycan structures.
-
O-linked glycosylation – addition of glycans to the oxygen atom of serine or threonine residues. Unlike N-glycans, O-glycosylation lacks a strict consensus motif and is initiated directly in the Golgi. O-glycans are often shorter but can form highly diverse branched structures.
Other specialized forms include C-mannosylation (attachment of mannose to tryptophan residues), glypiation (anchoring proteins to membranes via glycosylphosphatidylinositol, or GPI anchors), and less common modifications such as tyrosine or hydroxylysine glycosylation.
2.2 Structural Diversity of Glycans
Glycans are constructed from a limited set of monosaccharides (e.g., glucose, galactose, mannose, N-acetylglucosamine, fucose, and sialic acid), yet the possibilities for linkage, branching, and modification generate immense structural variety. For example:
-
Branching patterns determine recognition by lectins and receptors.
-
Terminal modifications, such as sialylation or fucosylation, influence immune responses and cell–cell communication.
-
Isomerism (different linkage orientations, such as α2,3 vs. α2,6 sialylation) can dramatically change biological activity even when the composition is identical.
2.3 Enzymatic Machinery and Regulation
The biosynthesis of glycans depends on a large family of glycosyltransferases (enzymes that add sugars) and glycosidases (enzymes that trim them). These enzymes act in a highly coordinated but non-templated manner, influenced by enzyme expression levels, substrate availability, and subcellular localization. As a result, the same protein can carry slightly different glycan structures — a phenomenon known as microheterogeneity.
2.4 Functional Implications
The biological significance of glycosylation is vast:
-
Protein folding and stability – N-glycans assist in proper folding and protect proteins from degradation.
-
Trafficking and localization – glycans act as molecular zip codes, guiding proteins to their correct destinations.
-
Cell–cell communication – glycans mediate recognition events, such as those involving selectins in leukocyte trafficking or immune synapse formation.
-
Immune modulation – altered glycosylation patterns can either activate or suppress immune responses, influencing processes like cancer immune evasion.
In short, protein glycosylation represents a dynamic and multifunctional layer of biological regulation. Its complexity is both a challenge and an opportunity: a challenge because structural analysis is technically demanding, and an opportunity because even small glycan changes can reveal critical insights into health and disease.
3. “Sugar Code”: What It Encodes in Function
The concept of the “sugar code” refers to the idea that glycans act as molecular signals, encoding information that determines how proteins and cells behave. Unlike DNA, which conveys genetic instructions in a linear sequence, glycans use their structural complexity — branching, linkage types, and terminal decorations — to create a highly versatile language. This molecular code influences nearly every aspect of protein and cellular function.
3.1 Protein Folding, Stability, and Quality Control
N-linked glycans play a crucial role in protein quality control within the endoplasmic reticulum. During folding, glycans interact with molecular chaperones such as calnexin and calreticulin, ensuring that proteins reach their proper conformation before exiting the ER. If folding fails, glycans mark the protein for degradation through the ER-associated degradation (ERAD) pathway. This sugar-based checkpoint protects the cell from misfolded or aggregation-prone proteins.
3.2 Cellular Communication and Adhesion
Glycans extend outward from the cell surface, forming a dense molecular layer known as the glycocalyx. This structure acts as an interface for cell–cell and cell–environment interactions. For example:
-
Selectin–glycan binding regulates leukocyte rolling during immune surveillance and inflammation.
-
Integrin–glycan interactions influence cell adhesion and migration, crucial in processes like wound healing and cancer metastasis.
-
Pathogens, including viruses and bacteria, exploit glycan receptors to enter host cells. Influenza viruses, for instance, specifically recognize sialic acid linkages to determine host range and infectivity.
3.3 Immune Recognition and Regulation
The immune system is highly sensitive to glycan signatures:
-
Self vs. non-self discrimination – Host glycans, such as sialylated structures, can suppress immune activation, while pathogen-associated glycans trigger strong responses.
-
Antibody function – The Fc region of antibodies carries N-glycans whose composition modulates effector functions such as antibody-dependent cellular cytotoxicity (ADCC).
-
Immune evasion in cancer – Tumor cells often remodel their surface glycosylation (e.g., increased sialylation) to create an immunosuppressive environment, allowing them to escape immune attack.
3.4 Glycosylation in Disease
Aberrant glycosylation patterns are hallmarks of many human disorders:
-
Cancer – Overexpression of specific glycans, such as sialyl-Tn antigen, is associated with tumor progression and poor prognosis.
-
Congenital Disorders of Glycosylation (CDGs) – Mutations in glycosylation enzymes disrupt normal protein modification, leading to multisystem diseases with neurological and developmental symptoms.
-
Neurodegenerative diseases – Altered glycan patterns have been implicated in Alzheimer’s and Parkinson’s disease, potentially affecting protein aggregation and synaptic signaling.
3.5 Biomarker Potential of the Sugar Code
Because glycan structures reflect cellular states, they serve as sensitive biomarkers. Serum glycoprotein profiles can indicate early disease onset, predict disease progression, or monitor therapeutic response. For example, glycoproteomic profiling of blood samples has revealed cancer-specific glycan signatures that may complement genomic and proteomic biomarkers in precision medicine.
4. Technologies and Methods in Glycoproteomics
Studying the sugar code requires advanced technologies capable of detecting and deciphering the immense structural diversity of glycans. Glycoproteomics combines sample enrichment, mass spectrometry (MS), and bioinformatics analysis to identify glycosylation sites and characterize glycan structures. Each step in the workflow is critical to ensure sensitivity, accuracy, and reproducibility.
4.1 Sample Preparation and Enrichment
One of the major challenges in glycoproteomics is the low abundance and structural heterogeneity of glycoproteins compared with other proteins. To overcome this, selective enrichment strategies are employed:
-
Lectin affinity chromatography – Lectins, proteins that recognize specific glycan motifs, can be used to isolate subsets of glycoproteins (e.g., concanavalin A for mannose-rich glycans).
-
Hydrophilic interaction chromatography (HILIC) – Separates glycopeptides based on polarity, useful for capturing a broad range of glycosylated peptides.
-
Metabolic labeling – Cells are fed sugar analogs containing chemical tags, which are incorporated into glycans and later used for selective enrichment.
-
Enzymatic digestion approaches – Peptide-N-glycosidase F (PNGase F) is commonly used to release N-glycans, enabling site-specific identification.
Careful sample preparation ensures that glycosylation signals are not lost amidst the overwhelming background of non-modified proteins.
4.2 Mass Spectrometry Workflows
Mass spectrometry has become the cornerstone of glycoproteomics because it can simultaneously measure peptide backbones and glycan modifications. Depending on research objectives, several strategies are applied:
-
Bottom-up glycoproteomics – Proteins are digested into peptides and glycopeptides for analysis. This is the most widely used approach but may lose information about intact glycoproteins.
-
Middle-down approaches – Larger peptide fragments are retained, providing more structural context about glycosylation sites.
-
Top-down glycoproteomics – Intact proteins are analyzed directly, preserving the full complexity of glycosylation patterns, though technically more challenging.
Different fragmentation techniques are employed to characterize glycans:
-
Collision-induced dissociation (CID) and higher-energy collisional dissociation (HCD) tend to fragment glycans first, providing glycan composition but often obscuring peptide information.
-
Electron-transfer dissociation (ETD) preserves glycan structures while breaking peptide backbones, enabling site localization.
-
Hybrid approaches (e.g., EThcD) combine both peptide and glycan fragmentation for more comprehensive data.
4.3 Computational and Bioinformatics Tools
The complexity of glycan structures demands specialized algorithms and databases:
-
Database-driven annotation – Tools such as UniCarb-DB and GlycoWorkbench help assign glycan structures based on MS/MS spectra.
-
De novo sequencing algorithms – Applied when database matches are unavailable, reconstructing glycan structures directly from spectra.
-
False discovery rate (FDR) estimation – Essential for reliable glycopeptide identification.
-
Integration with proteomic pipelines – Many proteomics platforms now include glycoproteomics modules, facilitating large-scale studies.
Bioinformatics is a rapidly evolving frontier, as accurate annotation remains a bottleneck due to glycan isomerism and structural ambiguity.
4.4 Recent Advances
The last few years have seen notable innovations in glycoproteomics:
-
Spatial glycoproteomics – Combining imaging mass spectrometry with glycoprotein analysis to map glycosylation in tissues.
-
Single-cell glycoproteomics – Emerging methods aim to profile glycan heterogeneity at the single-cell level, critical for studying tumor microenvironments.
-
Multi-omics integration – Linking glycoproteomics with transcriptomics and metabolomics to reveal systemic regulatory networks.
-
Artificial intelligence and machine learning – Applied to predict glycan structures, improve spectral annotation, and uncover patterns invisible to traditional methods.
5. Technical and Biological Challenges in Glycoproteomics Research
Despite rapid advances, glycoproteomics remains one of the most technically demanding branches of proteomics. The intrinsic complexity of glycans, combined with experimental and computational barriers, makes comprehensive analysis difficult. Understanding these challenges is crucial both for interpreting existing studies and for driving innovation in the field.
5.1 Structural Complexity and Heterogeneity
Unlike nucleic acids and proteins, glycans are synthesized by non-template-driven processes, resulting in an enormous variety of structures. Even a single glycosylation site can host multiple glycan forms (microheterogeneity), and the same glycan motif can appear on different proteins. This heterogeneity makes it nearly impossible to capture a “complete” glycoproteome in a single experiment.
5.2 Technical Sensitivity and Sample Loss
Glycoproteins often exist at low abundance relative to the total proteome. Enrichment methods help but can introduce bias (e.g., lectin affinity favoring certain glycan motifs). Additionally, glycopeptides tend to ionize poorly in mass spectrometry, leading to underrepresentation in datasets. Sample preparation also risks losing fragile glycan modifications during digestion or separation.
5.3 Fragmentation Challenges in Mass Spectrometry
While MS is powerful, glycan fragmentation is unpredictable. Conventional methods (CID, HCD) preferentially fragment glycans, sometimes leaving peptide backbones insufficiently characterized. ETD provides complementary information but requires higher sample amounts and optimized conditions. As a result, glycan structure and site localization are often incomplete, particularly for complex or branched glycans.
5.4 Data Analysis Bottlenecks
The computational side of glycoproteomics presents significant obstacles:
-
Database limitations – Unlike proteomics, where protein databases are well-curated, glycan databases remain incomplete, especially for rare modifications.
-
Isomer discrimination – MS cannot always distinguish glycan isomers that share the same composition but differ in linkage or branching.
-
Computational load – De novo sequencing algorithms are computationally intensive and prone to false positives.
-
Standardization issues – Different laboratories use different pipelines, making results difficult to compare across studies.
5.5 Biological Variability
Glycosylation is highly context-dependent, influenced by cell type, developmental stage, environment, and disease state. This variability complicates efforts to define “normal” vs. “abnormal” glycosylation. Moreover, dynamic changes in glycan expression over time make longitudinal studies challenging.
5.6 Reproducibility and Standardization
Currently, no universally accepted workflows exist for glycoproteomic studies. Variations in sample prep, instrumentation, and analysis pipelines lead to reproducibility concerns. For clinical applications, this lack of standardization is a major obstacle, as biomarker discovery requires highly reproducible and validated protocols.
In summary, glycoproteomics faces significant barriers in structural complexity, technical sensitivity, and data interpretation. However, acknowledging these limitations provides a roadmap for innovation — from better enrichment chemistries to AI-powered data analysis — that will move the field closer to routine, high-throughput applications.
6. Glycoproteomics Applications in Medicine and Biotechnology
The ability to decode the glycoproteome has far-reaching implications in both medicine and biotechnology. Because glycosylation patterns are tightly regulated yet highly dynamic, glycoproteomics offers unique opportunities to identify disease-specific markers, develop novel therapeutics, and optimize biologics manufacturing. Below are the major areas where glycoproteomics is driving innovation.
6.1 Clinical Diagnostics and Biomarker Discovery
Aberrant glycosylation is a hallmark of many pathological conditions, including cancer, autoimmune diseases, and neurodegenerative disorders. Glycoproteomics enables the systematic identification of glycan alterations associated with disease states:
-
Cancer biomarkers: Altered fucosylation or sialylation on serum glycoproteins has been linked to early-stage liver, breast, and pancreatic cancers, providing new avenues for minimally invasive diagnostics.
-
Cardiovascular disease: Changes in glycosylation of acute-phase proteins such as alpha-1-acid glycoprotein can reflect inflammatory status and cardiovascular risk.
-
Neurodegeneration: In Alzheimer’s disease, glycoproteomic profiling of cerebrospinal fluid reveals glycan structures associated with amyloid pathology and neuroinflammation.
By integrating glycoproteomics with other omics data, researchers are now developing multi-parameter diagnostic signatures with improved sensitivity and specificity.
6.2 Therapeutic Target Identification
Glycoproteomics also facilitates the discovery of therapeutic targets. Cell-surface glycoproteins often act as receptors or adhesion molecules, making them accessible points of intervention:
-
Immuno-oncology: Immune checkpoint proteins such as PD-1 and PD-L1 are heavily glycosylated, and modulation of their glycan structures influences immune evasion. Mapping these modifications helps optimize antibody therapies.
-
Infectious diseases: Viruses such as HIV and SARS-CoV-2 cloak themselves with glycosylated proteins to evade immune detection. Glycoproteomics provides insights into vulnerable glycan sites that can be exploited for vaccine design.
6.3 Biopharmaceutical Development
Many biotherapeutics, particularly monoclonal antibodies and fusion proteins, are glycoproteins. The efficacy, stability, and half-life of these biologics are strongly dependent on their glycosylation profiles. Glycoproteomics is therefore indispensable in:
-
Quality control: Ensuring batch-to-batch consistency in glycan patterns to maintain therapeutic performance.
-
Antibody engineering: Modifying Fc glycosylation to enhance antibody-dependent cellular cytotoxicity (ADCC) or anti-inflammatory activity.
-
Biosimilar development: Glycoproteomics helps establish comparability between original biologics and biosimilar products, which is critical for regulatory approval.
6.4 Vaccine Design and Immunotherapy
The role of glycosylation in pathogen recognition has led to new classes of vaccines and immunotherapies:
-
Glycoconjugate vaccines: Attaching bacterial polysaccharides to protein carriers improves immunogenicity and long-term protection.
-
Cancer glycopeptide vaccines: Tumor-associated carbohydrate antigens (TACAs) serve as targets for vaccine development aimed at eliciting glycan-specific immune responses.
-
Adjuvant discovery: Glycoproteomic screening of immune cell receptors helps identify glycan ligands that modulate immune activation.
6.5 Regenerative Medicine and Tissue Engineering
Beyond drugs and vaccines, glycoproteomics also contributes to regenerative medicine. Glycoproteins in the extracellular matrix regulate stem cell differentiation, wound healing, and tissue repair. Characterizing these glycan cues allows the design of biomaterials that better mimic the natural cellular environment, thereby improving outcomes in tissue engineering.
7. Decoding the Sugar Code: Implications for Precision Medicine and Biotechnology
Glycoproteomics has emerged as a pivotal discipline at the intersection of biology, chemistry, and data science. By systematically analyzing the sugar code of proteins, researchers are uncovering a hidden layer of biological regulation that rivals the genetic and proteomic codes in complexity and significance. The structural diversity of glycans, once seen as an analytical obstacle, is now recognized as a rich source of biological information with direct implications for medicine and biotechnology.
The progress achieved in glycoproteomics over the past decade is remarkable: from improved enrichment methods and advanced mass spectrometry platforms to AI-assisted data interpretation and glycoengineering technologies. These innovations have enabled researchers to map glycosylation with increasing depth and precision, transforming what was once considered an inaccessible field into a powerful toolkit for biomedical discovery.
Applications are already tangible. In clinical diagnostics, glycoproteomics has yielded promising biomarkers for cancer, cardiovascular disease, and neurodegenerative disorders. In therapeutics, it guides the design and quality control of monoclonal antibodies, biosimilars, and vaccines. In biotechnology, it drives the engineering of glycoproteins with tailored functions. Looking ahead, the integration of glycoproteomics with genomics, metabolomics, and single-cell technologies will enable a holistic understanding of health and disease.
Despite remaining challenges — including the need for standardized workflows, improved sensitivity, and broader clinical validation — the trajectory of the field is clear. Glycoproteomics is evolving from a specialized research area into a cornerstone of precision medicine, next-generation therapeutics, and biotechnological innovation.
In essence, unveiling the sugar code of proteins is more than a scientific pursuit; it is a key to unlocking new dimensions of human biology. As technologies advance and interdisciplinary collaboration deepens, glycoproteomics will continue to shape the future of healthcare, offering insights that were unimaginable just a generation ago.
Reference
1. Varki, A. (2017). Biological roles of glycans. Glycobiology, 27(1), 3–49. https://doi.org/10.1093/glycob/cww086
2. Reily, C., Stewart, T. J., Renfrow, M. B., & Novak, J. (2019). Glycosylation in health and disease. Nature Reviews Nephrology, 15(6), 346–366. https://doi.org/10.1038/s41581-019-0129-4
3. Rudd, P. M., & Dwek, R. A. (1997). Glycosylation: Heterogeneity and the 3D structure of proteins. Critical Reviews in Biochemistry and Molecular Biology, 32(1), 1–100. https://doi.org/10.3109/10409239709082569
4. Narimatsu, H., Kaji, H., Vakhrushev, S. Y., Clausen, H., & Wandall, H. H. (2018). Glycoproteomics: Mass spectrometry-based methods and applications. Current Opinion in Structural Biology, 56, 135–146. https://doi.org/10.1016/j.sbi.2018.12.010
5. Riley, N. M., & Bertozzi, C. R., & Pitteri, S. J. (2020). Glycoproteomics: Past, present and future. Analytical Chemistry, 92(1), 148–166. https://doi.org/10.1021/acs.analchem.9b04223
6. Ruhaak, L. R., Miyamoto, S., & Lebrilla, C. B. (2013). Developments in the identification of glycan biomarkers for the detection of cancer. Molecular & Cellular Proteomics, 12(4), 846–855. https://doi.org/10.1074/mcp.R112.026799
7. Alley, W. R., & Novotny, M. V. (2010). Structural glycoproteomics: Understanding the diversity of glycan structures and functions. Annual Review of Analytical Chemistry, 3, 525–556. https://doi.org/10.1146/annurev.anchem.111808.073727
8. Yang, W., Ao, M., Hu, Y., Li, Q. K., Zhang, H. (2021). Mapping the glycoproteome of human tissues. Nature Communications, 12, 5282. https://doi.org/10.1038/s41467-021-25523-0
9. Adamczyk, B., Tharmalingam, T., & Rudd, P. M. (2012). Glycans as cancer biomarkers. Biochimica et Biophysica Acta (BBA) - General Subjects, 1820(9), 1347–1353. https://doi.org/10.1016/j.bbagen.2011.12.001
10. Zhang, H., Li, X. J., Martin, D. B., & Aebersold, R. (2003). Identification and quantification of N-linked glycoproteins using hydrazide chemistry, stable isotope labeling and mass spectrometry. Nature Biotechnology, 21, 660–666. https://doi.org/10.1038/nbt829
Next-Generation Omics Solutions:
Proteomics & Metabolomics
Ready to get started? Submit your inquiry or contact us at support-global@metwarebio.com.
